What is synthetic data?
Synthetic data is artificial data that mimics real data but the individual records are not those of actual people. It can be used to train AI models if there is not enough real data or to balance biased datasets. Lately, it is also seen as a chance to overcome privacy issues and provide fine-granular, individual records without (supposedly) any reference to real people.
If synthetic data is generated successfully, it holds the promise of overcoming the utility-privacy trade-off by providing high utility (and flexibility) while simultaneously providing high privacy.
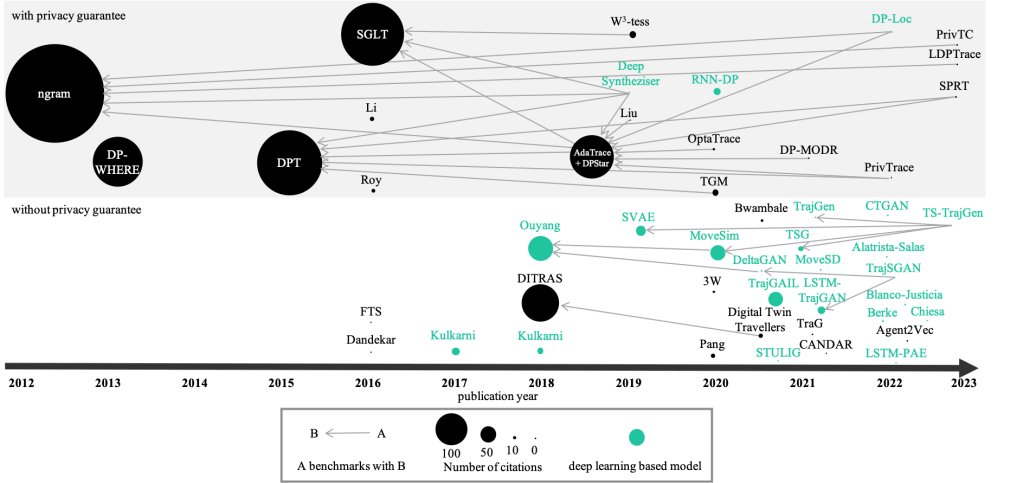
In the recent decade, there has been an increasing number of publications on synthetic mobility data generation. To gain a better understanding of the proposed models and the expected utility as well as privacy from such models, we conducted a systematic literature review and deep-dived into the topic by reviewing 50+ papers.
Main findings
- Mobility data is heterogeneous and encompasses a variety of different datasets. Based on applications in real-life contexts, we see mainly three categories of data that models aim to synthesize: trips (e.g., taxi trips), user movements (e.g., restaurant check-in history of individuals), and city population (e.g., household survey). Depending on the category, models come with different requirements for input data and limitations on output data.
- There is a wide range of modeling approaches utilized (e.g., Markov models, neural networks, reinforcement learning); especially in recent years, deep learning approaches have become increasingly popular.
- Mobility data can be represented in various ways, for example, models are based on approaches for time series data (a trajectory represented as a sequence of locations), natural language processing (locations considered as a vocabulary and a trajectory corresponds to a sentence), or image data (a trajectory visualized on a map and processed as an image).
> Knowledge about the algorithm and suitable data is needed. There is no algorithm that suits all types of mobility datasets.
- The time component is either omitted or highly simplified.
- Other attributes (e.g., traffic mode, demographics, travel purpose) of mobility datasets are hardly taken into account.
- Only modeled attributes can be reproduced well, i.e., generalization to arbitrary use cases is not possible.
- No common prediction or classification tasks are suitable to use as downstream tasks for model evaluation. For example, for medical data, such a downstream task can be the determination of a diagnosis.
- Instead, a set of similarity measures is usually employed to evaluate models for mobility data. We group these measures and elaborate on them. As there are no standardized evaluations, models are difficult to compare and a definition of high utility can hardly be established.
- No application tests in real context so far.
> No model can yet offer complete flexibility.
> The usefulness of synthetic data is doubtful; possibly even misleading if users are not aware of limitations.
- Many procedures come without privacy guarantees and evaluations – synthetic data in itself is not a privacy guarantee! However, quite a few also provide differential privacy guarantees.
> Models without privacy guarantees should be used with care. In the worst case, a (deep learning) model learns the original data perfectly and simply reproduces the original dataset.
If you want to know more, here you can find the entire publication:

A. Kapp, J. Hansmeyer, und H. Mihaljević, „Generative Models for Synthetic Urban Mobility Data: A Systematic Literature Review“, ACM Comput. Surv., July 2023, doi: 10.1145/3610224.

Leave a reply to pizzinozadyn92 Cancel reply