Using the earth mover’s distance to quantify the similarity between two maps with implementations in Python and R.
When you implement a privacy measure, e.g., adding noise to data, you are interested to know how similar your noisy data is compared to your original data. Therefore, there are various similarity metrics to quantify the difference between the original and the new distribution. For geospatial data, there are specific challenges:
The Scenario
Let’s assume you have a map that shows the distribution of people within Berlin – e.g., data collected through cellular networks, GPS tracking, stationary sensors, or simply a survey. You aggregate the data spatially (in this example we use the “Planungsräume Berlin from the Geoportal Berlin” as a tessellation) and get the following result:
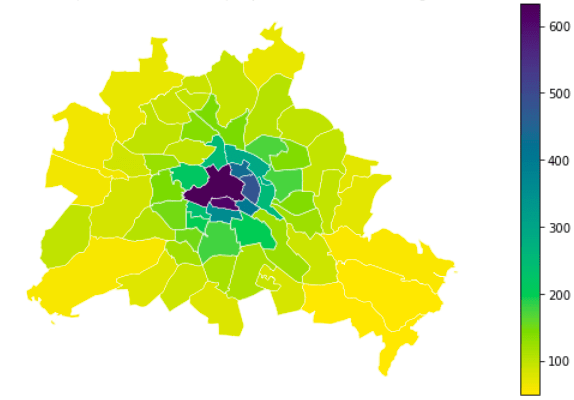
A few weeks later you collect the data again (Or in the context of privacy measures: you add noise to the data). Now imagine two scenarios. In scenario 1 you get the following new output:
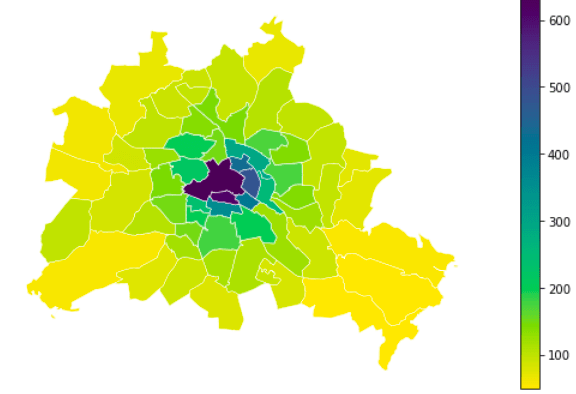
You can see a change of 100 people who are recorded less within one tile and more in the neighboring tile.
In scenario 2 you see the following:
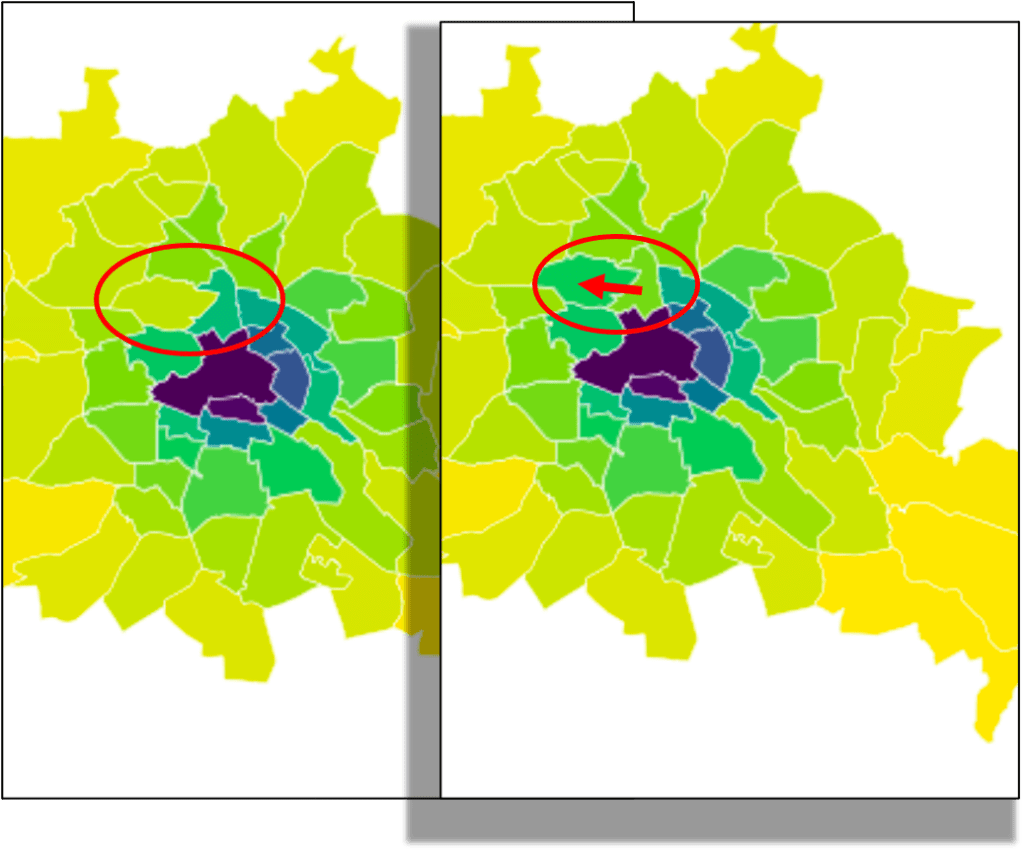
In scenario 2 there are 100 people less in the same tile as in scenario two but 100 people more in a tile at the outskirts of the city.
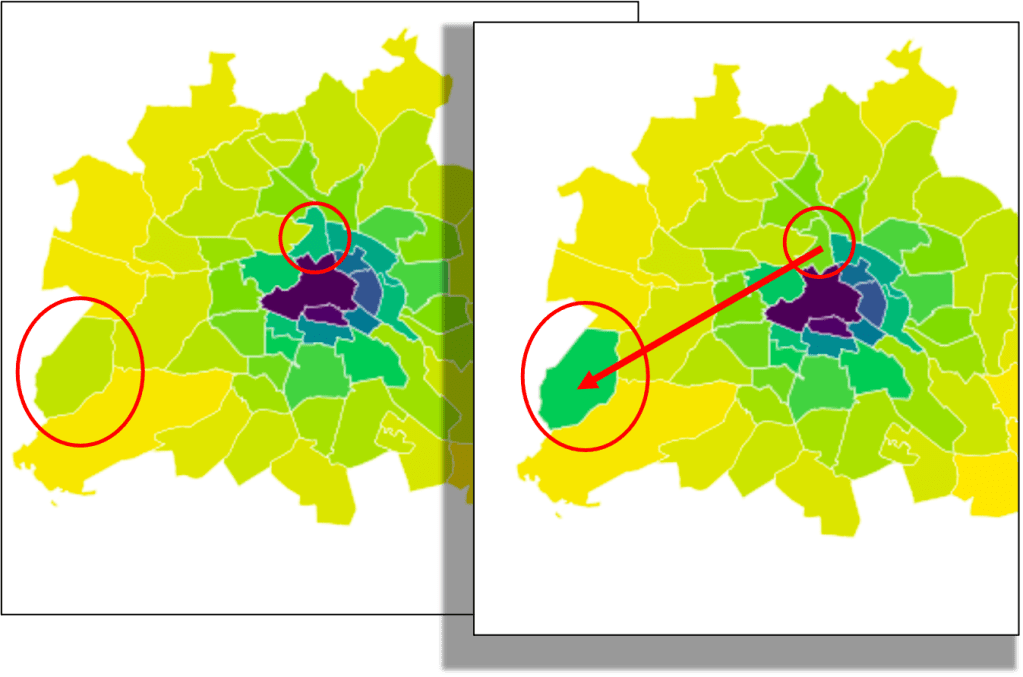
Intuitively, the first scenario looks more similar to the original data than the second. In both scenarios, 100 people moved from the same origin tile to another tile. Though in scenario 1 the new tile is a neighboring tile of the origin while in scenario 2 the tile is at the outskirts of the city.
One could imagine explanations for the changes in scenario 1, as for example usual variability in people’s behavior, or maybe a coffee shop down the street had a special offer. Or it could even be due to inaccuracies in the data collection instrument – maybe there are many people right at the border of the two regions and the tracked GPS signal is not accurately assigned to the correct region. The movement to a region far away in scenario 2 seems to be a more significant change. Intuitively the pattern of the map has changed. One reason, this change seems bigger, is because it is more effort to move multiple kilometers from the original location away than it is to move a few hundred meters.
But how can you measure this (dis-)similarity?
Measuring similarity
Common measures that compare the similarity between distributions do not account for spatial distance. E.g., the mean absolute percentage error (by how many percent does each original tile diverge from its scenario equivalent?), the Jensen-Shannon metric (how similar are two probability distributions?), or the correlation will be similar for both scenarios. This is because the spatial component is not being considered and all tiles are treated equally.
Mean mean absolute percentage error scenario 1: 2.41%
Mean mean absolute percentage error scenario 2: 2.41%
Jensen-Shannon distance scenario 1: 0.0401
Jensen-Shannon distance scenario 2: 0.0401
Biserial correlation coefficient scenario 1: 0.9893
Biserial correlation coefficient scenario 2: 0.9893Earth Mover’s Distance (Wasserstein metric)
To capture the spatial distance, we need to use a measure that can account for that. The Wasserstein metric, also called earth mover’s distance (EMD), can do exactly this.
Citing from this detailed explanation of the EMD: “Intuitively, given two distributions, one can be seen as a mass of earth properly spread in space, the other as a collection of holes in that same space. Then, the EMD measures the least amount of work needed to fill the holes with earth. Here, a unit of work corresponds to transporting a unit of earth by a unit of ground distance.” Clear and illustrative explanations of the earth mover’s distance are also given here and here.
Python Implementation
Now we have the theory, but how do we implement this in python?
The implementation by Scipy of the Wasserstein Distance only works with 1D distributions. But we have a 2D distribution – latitude and longitude.
The EMD is also used as a metric to compare the similarity between images (see, e.g., this). This is why there is an implementation by the OpenCV (Open Source Computer Vision Library) for 2D distributions, which we can use for our purposes.
Unfortunately, the documentation is not very intuitive to understand but thankfully there is a blog article by Sam van Kooten who explains this nicely. His illustration also shows visually, how the earth mover’s distance works for images:
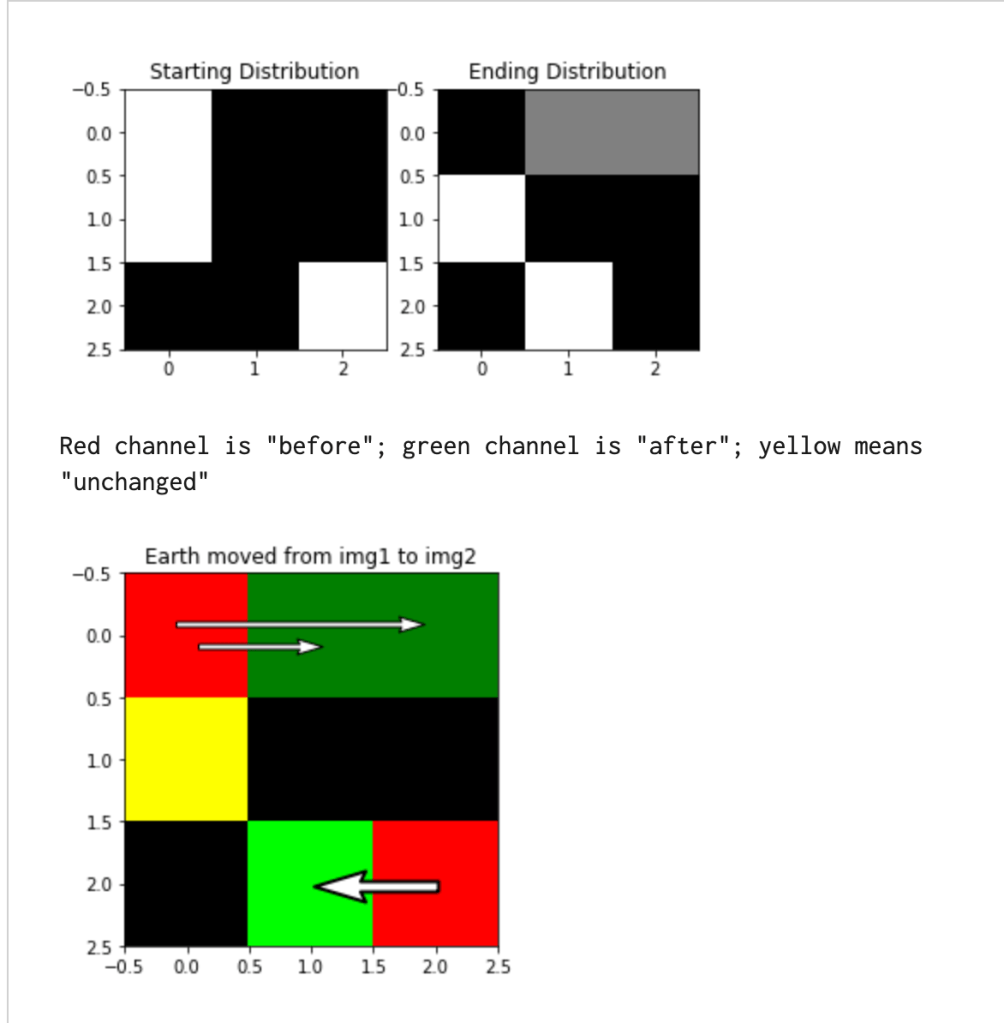
So how does the CV2 implementation work in detail? Let’s have a look at the documentation:
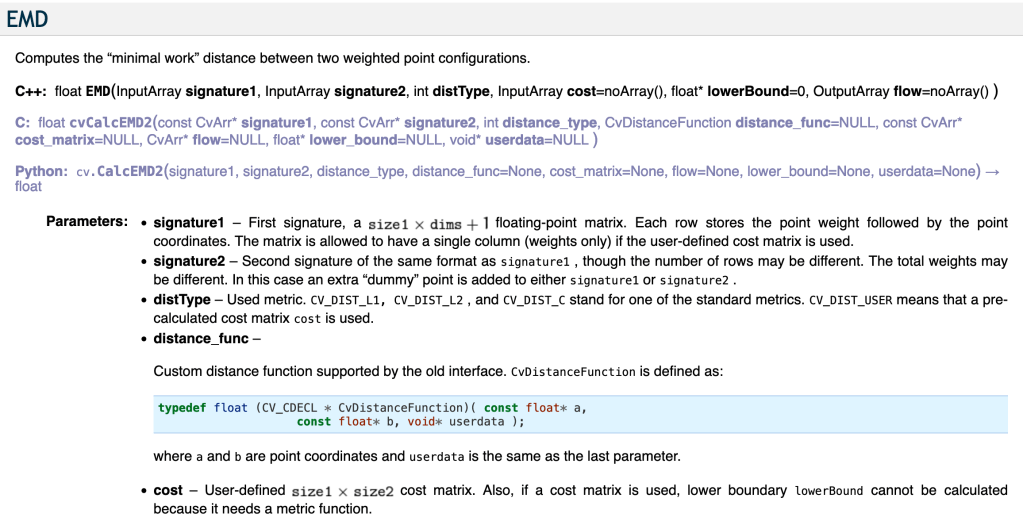
According to the documentation, we need a signature as input format. Let’s assume we have a nine-pixel image and each pixel holds one value. We can represent this image with the following matrix:
[2,3,5
1,2,4
2,1,2]
Then we can assign each pixel in the matrix a coordinate:
[(0,0), (0,1), (0,2)
(1,0), (1,1), (1,2)
(2,0), (2,1), (2,2)]
With this information, we can construct a signature of size = 9 and with dims=2, where each row hold the values (value, x_coordinate, y_coordinate):
[2, 0,0,
3, 0,1,
5, 0,2,
1, 1,0,
2, 1,1,
4, 1,2,
2, 2,0,
1, 2,1,
2, 2,2]For our use case, we cannot use the implementation of Sam van Kooten to translate our data into a signature, because we do not have a raster where each cell has a similar distance to its neighbors. Therefore, we cannot construct the coordinates as easily as just described in the example.
First of all, we need to define a single point for each tile in our tessellation. For simplicity, we take the centroid.
Then we need to consider the following: We cannot simply use the geographical coordinates and compute the euclidean distance (this would only be possible if the earth was flat).
Therefore, we have two options:
- We project our centroids to a projected coordinate reference system (CRS) and take those coordinates as input to construct our signature. (Here you can learn more about the difference between a geographical and a projected CRS).
- We make use of the option in the
cv2.EMDfunction to use a customcost_matrixinstead of passing coordinates in the signature. We can use the geographical coordinates to compute the haversine distance between all centroids and costruct a cost matrix.
Option 1: use projected coordinates
Which will result in the following output:
Earth movers distance scenario 1 (CRS: EGSG:3035):
30 meters
Earth movers distance scenario 2 (CRS: EGSG:3035):
196 metersOne drawback of this method is, that you need to use a properly projected CRS for your data, otherwise your results might not be accurate.
I used the EGSG:3035 which is suitable for Europe. If I would have used, for example, the World Mercator EPSG:3395 projection, the results would have been slightly different, as this projection is not perfectly accurate for Berlin:
Earth movers distance scenario 1 (CRS: EGSG:3395):
50 meters
Earth movers distance scenario 2 (CRS: EGSG:3395):
322 metersIf you are not familiar with the correct usage of different CRS, option two might be better suited:
Option 2: construct a custom cost_matrix with the haversine distance
We compute a custom cost matrix for all coordinate pairs using the haversine distance.
For the cost matrix, we need to define the distance between all points. All points within the first distribution (signature 1) to all points in the second distribution (signature 2). In our case, the points in both distributions are the same, therefore, each distance is included twice (A-B and B-A). In our case, this is the same distance but one could also use asymmetric distances (e.g., you have an uphill location and include the effort needed to go uphill while it saves work to go downhill).
The cost matrix has a dimension of n x m where n is the number of points in the first distribution (signature 1) and m is the number of points in the second distribution (signature 2). In our case n=m, but for the earth mover’s distance, the points in the first distribution do not have to be the same number or the same points at all as within the second distribution.
We compute the EMD with a cost matrix as follows:
Earth movers distance scenario 1: 30 meters
Earth movers distance scenario 2: 196 metersThe result can now be interpreted as follows:
In scenario 1 each person has to move 30 meters on average to change the distribution from the original to scenario 1.
In scenario 2 this is 196 meters on average per person.
That way, we have a quantified difference between scenarios 1 and 2.
Implementation in R
See this code for the same implementation in R.

Leave a comment